话说上次在docker swarm里面实现了MongoDB复制集之后,可以愉快地重启运行复制集节点的机器了,存储的资料也不担心硬盘挂掉而丢失, 真是快哉~
所以,再接再厉,把Redis和Memcached也迁移到docker swarm跑起来。
先来说说memcached的业务场景及特性,知己知彼,百战百胜嘛

memcached场景之一
用户要是忘记了密码,或者新注册用户等,总之在需要接收手机短信验证码的时候,得先输入正确的验证码,应用在生成图形验证码的时候,会往memecached里面写入验证码的哈希值,跟用户输入转换的哈希值作比较。
所以,这是一个对可用性有要求的场景,辣么,memcached必须不能单实例跑了(你看上图是一群)。
memcached特性
- 在Memcached中可以保存的item数据量是没有限制的,只要内存足够;
- Memcached单进程最大使用内存为2GB,要使用更多内存,可以分别在不同端口启动多个Memcached进程;
- Memcached是一种无阻塞的socket通信方式的服务,基于libevent库,由于无阻塞通信,对内存读写速度非常之快;
- Memcached分为服务器和客户端,可以配置多个服务器和客户端,应用于分布式的服务非常广泛;
- Memcached作为小规模的数据分布式平台是非常高效的;
memcached存在的问题
本身没有内置分布式功能,无法实现使用多台memcachd服务器来存储不同的数据,最大程度的使用相同的资源。服务器之间没有任何通信,并且不进行任何数据复制备份,所以当任何服务器节点出现故障时,会出现单点故障,如果需要实现高可用,就需要通过其他方式。
那么有问题,就会有解决方案,来张图:
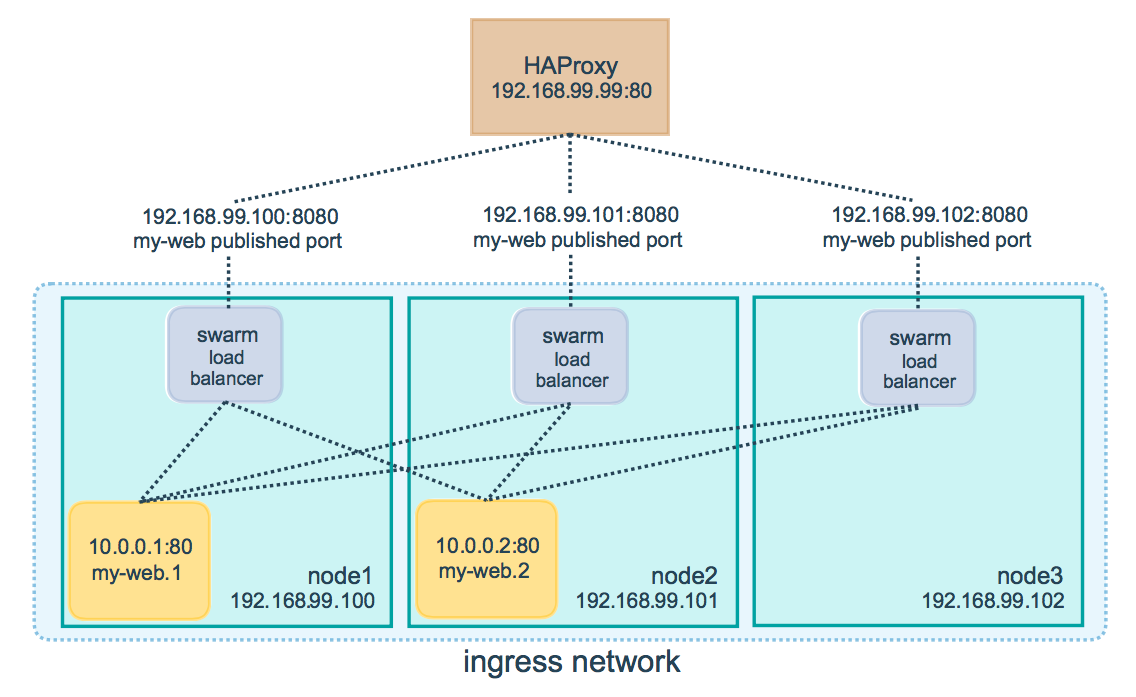
这次要用到跨主机通讯,当您需要在不同Docker主机上运行的容器进行通信时,或者当多个应用程序使用swarm服务协同工作时,Overlay networks是最佳选择。
haproxy之上是应用,不考虑会话保持之类,纯粹在应用和memcached之间充当一个tcp负载均衡。
这里使用默认的overlay网络
为什么要加HAproxy?
虽然docker的overlay网络能实现内部的负载均衡,但是万一swarm内运行服务的某节点挂了,IP都不通,那如何是好啊,该加还是得加。
那HAproxy挂了呢,挂了就上keepalived,利用vrrp协议,避免单点,这里不铺开。
先建立memcached的service
1 | docker service create --name memcached --replicas=3 -p 11211:11211 memcached |
名为memcached且开放了11211端口的service,三个swarm节点上都有容器实例。
启动并配置HAproxy
配置文件相关配置段如下:
1 | frontend haproxy_memcached |
balance source
haroxy 将用户IP经过hash计算后 指定到固定的真实服务器上(类似于nginx 的IP hash 指令)
172.16.10.1~3
运行memcached service的docker swarm节点IP
容器服务还有自动重新启动策略,重启策略控制Docker守护程序在退出后是否重新启动容器。Docker支持以下重启策略:none、on-failure、any, 默认为any。
OK,打完收工。