工作需要,Let’s do it.

策略
- 事先确定Replica Set的成员数量,因为这跟能Replica Set中能容忍挂掉的成员数量有直接关系
- Replica Set中的voting成员数量要提前确定,MongoDB的Replica Set最大可以拥有50个成员,其中包括最多7个voting成员
- 部署奇数成员数的Replica Set
- 操作系统采用Ubuntu16.04.4 LTS 64bit
- 原计划五台机器单机跑docker实例,也可以创建replica set ,但是日后还有其他测试要用到swarm环境,所以干脆一步到位,五台机器全部作为swarm node
IP规划
| Replica Set 角色 | swarm角色 | 物理机器名 | IP | CPU | 内存 |
|---|---|---|---|---|---|
| 主节点 | 管理节点 | docker-swarm01 | 192.168.0.233 | i5-4590 | 8G |
| 从节点 | 工作节点 | docker-swarm02 | 192.168.0.232 | Celeron G1840 | 8G |
| 从节点 | 工作节点 | docker-swarm03 | 192.168.0.242 | i7-4790 | 16G |
| 从节点 | 工作节点 | docker-swarm04 | 192.168.0.241 | i7-6700 | 8G |
| 从节点 | 工作节点 | docker-swarm05 | 192.168.0.230 | i5-4590 | 8G |
按照表格规划好的,修改各机器的IP和机器名
这里我们使用五台机器搭建swarm集群,root账号操作,顺序如下:
- 准备工作,免密登录,初始化设置等。
- 替换系统的默认软件源为网易镜像源。
- 增加科技大docker安装源,安装好docker-ce最新稳定版本。
- docker hub镜像源替换为国内DaoCloud加速源。(你也可以用已有的docker hub加速器)
- 上传MongoDB测试数据(这一步可以提前上传到主节点),这里我上传到了docker-swarm01。
- 建立docker swarm,并把各节点加入swarm。
- 每个节点建立存放MongoDB的数据volume,并做好命名工作。
- 每个节点建立MongoDB Replica Set的节点service,并做好命名工作。
- 初始化MongoDB Replica Set。
- 还原备份数据到Replica Set中。
- 查看数据同步情况,确认同步完毕。
- 进行访问测试。
准备工作
1、配置IP地址,ubuntu16.04的话,修改/etc/network/interfaces文件即可。
2、配置Ansible与目标机器的ssh免密登录,这里以swarm01为例。
1 | # 生成ssh key |
3、修改/etc/ansible/hosts和/etc/hosts文件
不修改/etc/hosts的话,Ansible会报错
/etc/hosts文件加入以下内容:
1 | 192.168.0.233 swarm01 |
/etc/ansible/hosts文件加入以下内容:
1 | [swarm] |
替换系统的默认软件源为网易镜像源
1 | #这里采用Ansible的copy模块+修改好的sources.list文件上传到对应位置即可 |
增加科技大docker安装源,安装好docker-ce最新稳定版本
一键脚本在此 https://github.com/zhusas/docker-ce.init.git 这个脚本也包含了docker hub镜像源替换为国内自定义加速源。
这是之前写的一个脚本,用ansible的script模块可以使用,其内容也可以写成playbook,这里就直接用脚本操作,日后再完善playbook,放到Github上。
1 | #批量运行脚本 |
建立docker swarm,并把各节点加入swarm
以下端口必须保持畅通:
TCP port 2377 :swarm集群管理信息通讯端口
TCP and UDP port 7946 :swarm节点之间的通讯端口
UDP port 4789 : overlay网络通讯端口
如果你建立了一个加密的overlay网络 (–opt encrypted),你还徐确保 ip protocol 50 (ESP) 能够正常通讯。
下面开始操作:
1 | root@Ansible:/opt# ansible swarm01 -m shell -a "docker swarm init --advertise-addr 192.168.0.233" |
可以看到,建立了swarm管理节点之后,运行docker swarm join命令,swarm01会报“Error response from daemon: This node is already part of a swarm. Use “docker swarm leave” to leave this swarm and join another one.non-zero return code”,意思是提醒你这已经是swarm的一部分了,不过没关系,哈哈。swarm02~05已经顺利加入。
我们用命令看看

OK了。
这里提醒一下的是,一般服务器都是网卡,建立swarm时候,最好加上–listen-addr 参数。我这里测试的机器都是单网卡,影响不大。各位切记哦。
明确一下计划
基本计划是将MongoDB副本集的每个成员定义为单独的swarm服务,并使用docker service的约束参数来防止swarm的scaling特性将它们从数据卷移开,因为数据卷存放在每个节点上,没法跟着容器漂移到其他节点, 这保留了Docker提供的所有操作优势,同时消除了scaling故障恢复功能(会影响MongoDB副本集的可用性)。通过命令将MongoDB服务固定到与其数据卷相同的swarm节点,在每个节点上设置标签。 稍后在创建服务时,将在约束中使用这些标签。
给swarm各节点加标签
1 | root@Ansible:~# ansible swarm01 -m shell -a "docker node update --label-add mongo.rs=1 docker-swarm01" |
这步感觉不够优雅,此时playbook的价值就体现出来了。我这是为了展现详细步骤才这样。
建立MongoDB replica set在docker swarm的overlay专用网络
swarm跨节点通讯必备
1 | root@Ansible:~# ansible swarm01 -m docker_network -a "name=mongo_network driver=overlay" |
建立存放MongoDB的数据Volume
1 | root@Ansible:~# ansible swarm01 -m docker_volume -a "name=rsdata1" |
其他四台以此类推,建立volume。
建立完毕后,如下:
1 | root@Ansible:/opt# ansible swarm -a "docker volume ls" |
在swarm01(管理节点)上建立replica set各个节点服务
1 | docker service create --replicas 1 --network mongo_network --mount type=volume,source=rsdata1,target=/data/db --constraint 'node.labels.mongo.rs==1' -p 27017:27017 --name mongo_rs1 mongo:3.6 mongod --replSet "whmallRS" |
-p <发布端口>:<目标端口>
<目标端口>为Docker容器中所监听的端口,<发布端口>为Swarm集群中使得服务可以访问的端口。
–constraint ‘node.labels.mongo.rs==2’
这个参数作用是通过定义约束表达式来限制可以调度任务的节点,因为没做分布式存储,万一docker-swarm02上mongo.rs2这个服务飘到了docker-swarm05上去了,服务读取不到数据,那就懵逼了。
必须找行政妹子多搞几台PC做分布式存储,GlusterFS就不错。。。。。 必须的~~
看看状况
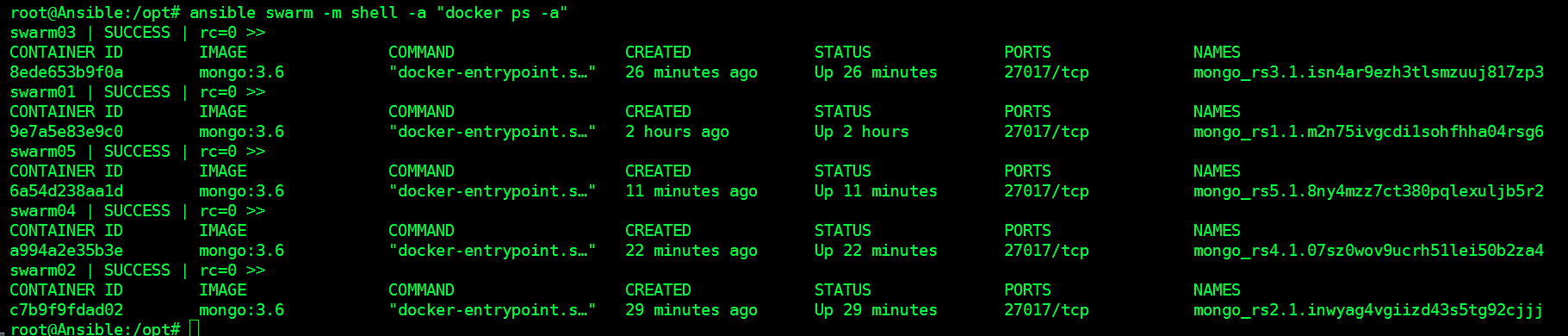
初始化MongoDB Replica Set
1 | #初始化命令 |
这一个基于docker swarm的MongoDB Replica Set就成了。
以上适合新建MongoDB副本集的情况,要是原来就是单实例,数据也备份了,要升级为副本集怎么办啊,那就继续往下看吧。
还原备份数据到Replica Set中
备份数据先准备好,解压到volume在宿主机上的路径
启动一个单节点的副本集
先删除原来的所有服务,回到docker swarm刚搭建完毕的时候
1 | #删除服务 |
1 | #启动一个单节点的副本集 |
OK,现在往副本集里面添加新成员,不过要注意两点:
1、当新添加的辅助节点的投票和优先级设置大于零时,在其初始同步期间,辅助节点仍然计为投票成员,即使它不能提供读取也不能成为主节点,因为其数据尚未一致。
2、这可能导致大多数投票成员在线但不能选出主要成员的情况。要避免这种情况,请考虑最初新添加的成员的priority的值为0,同样votes的值也为0。然后,一旦成员转换到SECONDARY状态,使用rs.reconfig()更新其priority和votes的值。
好,余下四个节点,依次建立副本集节点的swarm service
1 | docker service create --replicas 1 --network mongo_network --mount type=volume,src=rsdata2,dst=/data/db --constraint 'node.labels.mongo.rs==2' -p 27018:27017 --name mongo_rs2 mongo:3.6 mongod --replSet "whmallRS" |
添加mongo_rs2节点,数据自动开始同步
1 | #添加mongo_rs2到副本集中 |
余下节点按照以上方法依次加入。这要等一段时间,四个节点要同步数据,够呛。
重新配置副本集成员的权重与投票参数
这里有几点要注意:
1、数据全部同步完毕后,注意这是节点的priority和votes的值都为零,需要做调整,调整过程可能会引起主节点重新选举,所以建议此步骤在维护窗口期进行哦。
2、建议在维护窗口期间调整优先级设置。重新配置优先级可以强制当前主服务器降级,从而导致选举。在选举之前,副本集的主节点会关闭所有打开的客户端连接。除非你更改了副本集的默认读策略。
3、rs.reconfig()shell方法可以强制当前主节点降级,从而导致选举。当副本集主节点关闭时,mongod将关闭所有客户端连接。虽然这通常只需要10-20秒,但是建议在计划的维护期间进行这些更改。 避免重新配置包含不同MongoDB版本成员的副本集,因为验证规则可能因MongoDB版本而异。
1 | cfg = rs.conf(); |
第一个语句使用rs.conf()方法检索包含副本集的当前配置的文档,并将文档设置为本地变量cfg。
第二个语句将members [n] .priority值设置为members数组中的第二个文档。有关其他设置,请参阅副本集配置设置。 要访问数组中的成员配置文档,该语句使用数组索引而不是副本集成员的成员[n] ._ id字段。
最后一条语句使用修改过的cfg调用rs.reconfig()方法来初始化此新配置。
总结
- 使用分布式存储文件系统是一个好主意,如ceph、Gluster等。
- overlay网络中要确保运行副本集的跨主机容器能互相ping通,副本集依靠这个来检查节点心跳。
- 官方文档是必须看的。